So it seems I've landed myself lightspark, a free, open source Flash alternative and mediatomb, a plug and play media streaming app.
Media Tomb, which did not take an arm (ahem..) and a leg to get the source files for, uses assembly in two places that I can see, and they don't seem to be used elsewhere in the program at all (or at least outside of documentation).
The assembley is inline and looks a bit like this:
#ifdef ATOMIC_X86_SMP
#ifdef ATOMIC_X86
#error ATOMIC_X86_SMP and ATOMIC_X86 are defined at the same time!
#endif
#define ASM_LOCK "lock; "
#endif
#ifdef ATOMIC_X86
#define ASM_LOCK
#endif
#if defined(ATOMIC_X86_SMP) || defined(ATOMIC_X86)
#define ATOMIC_DEFINED
static inline void atomic_inc(mt_atomic_t *at)
{
__asm__ __volatile__(
ASM_LOCK "incl %0"
:"=m" (at->x)
:"m" (at->x)
:"cc"
);
}
If I'm reading this correctly, and there is a big chance I'm not, it's saying 'use this assembly only if you're using an x86 processor', otherwise, don't (more or less).
Lightspark however, has a lot more assembly for x86 working with video files, Chris and I looked at this, and determined that it had nearly 120 lines of the stuff and not only that, it uses NASM, an x86-only assembly compiler. However, it also appears that it should be rather straight forward to at least attempt to port to aarch64 assembly, if not try to get some C variations in there. Or at least see if there are C falls backs for that (I don't have the Lightspark code in front of me, so excuse the lack of examples for it.
Media Tomb should be a lot less work in terms of practical coding, Lightspark will likely take more time, but we'll see if the work is doable in the timeframe for this project.
I will be honest, I chose these two, for now at least, because they were both 0 on our list, and I didn't want to stray too far from my comfort zone,Lightspark is a flash alternative, and that is ALWAYS a plus in my mind. The less adobe I can put on a machine of any kind, the better. And a small media server app that isn't XBMC is good too, since somehow that thing has become all-pervasive. If Lightspark ends up being too much work, I may end up passing on it and moving on to a new package.
Friday, 21 February 2014
Saturday, 8 February 2014
SPO600 Assembler in Linux Packages lab 4
As part of group four, I ended up looking at Ogre and another group member looked into NSPR, discussing amongst ourselves the questions required to present to the rest of the class (that honour went to NSPR).
Ogre is an open source, multiplatform 3d rendering engine, used to make 3d applications (though I'd think it's most often used for game creation, where I first came across it) more so than any other type of application.
Most of the assembly code was spread across a small number of different source file directories, all located in the 'Main' Ogre directory, OgreMain in the 'src'. The assembler code seemed to be split into two separate uses. One was used for CPUID, in other words, to determine the type of CPU a particular user is running on when executing code, to determine which instruction set to follow. The other use seemed to be for atomics, and locking registers/the stack under specific circumstance, of which I couldn't 100% suss out from its use in the code (and my lack of experience with reading real world code on a regular basis). However, most of the time it still seemed to relate back to which set of CPU instructions were to be used. Oddly enough, within the code itself, the Assembler used for atomics made reference to its inclusion for only slight performance gains over C++ variations of the same coding.
One example of assembler's use in Ogre (found in OgreMain/src/nedmalloc/malloc.c.h.ppc):
It's not 100% apparent whether or not the Assembler in Ogre was written specifically for it, or taken from an existing library, though some of the comments included in-line with the code lead me to believe it was a little of both. From those same comments and the syntax used, the assembly code is meant for x86_64 and for most of it, more architecture agnostic versions (C++ specifically) exist, with slight performance loss. If the team is putting those kinds of comments in their own source code, I have to imagine that yes, this version of Ogre could relatively easily be ported to and built for aarch64, with very little difference to from the current x86_64 version.
Here is one of the comments on Assembly use in Ogre:
The other, NSPR, seems to only have a small amount of Assembly used for atomics in a small number of files, which could probably be rewritten in C/C++, especially since the Netscape Portable Runtime is meant to be platform neutral API - meant for web and server based applications (though in could be used for anything I suppose). However, speed might play a bigger role for NSPR than it would for CPUID function in Ogre. It was hard to tell whether the Assembler was hand written or taken from a library. My guess, library code. It could probably be built on aarch64 without too much trouble at the moment, even though the Assembly code here is for x86. I didn't access NSPR directly, as our group simply split the responsibility for each package to one a piece, and as such, I do not have any code snippets for it.
Ogre is an open source, multiplatform 3d rendering engine, used to make 3d applications (though I'd think it's most often used for game creation, where I first came across it) more so than any other type of application.
Most of the assembly code was spread across a small number of different source file directories, all located in the 'Main' Ogre directory, OgreMain in the 'src'. The assembler code seemed to be split into two separate uses. One was used for CPUID, in other words, to determine the type of CPU a particular user is running on when executing code, to determine which instruction set to follow. The other use seemed to be for atomics, and locking registers/the stack under specific circumstance, of which I couldn't 100% suss out from its use in the code (and my lack of experience with reading real world code on a regular basis). However, most of the time it still seemed to relate back to which set of CPU instructions were to be used. Oddly enough, within the code itself, the Assembler used for atomics made reference to its inclusion for only slight performance gains over C++ variations of the same coding.
One example of assembler's use in Ogre (found in OgreMain/src/nedmalloc/malloc.c.h.ppc):
/* place args to cmpxchgl in locals to evade oddities in some gccs */
int cmp = 0;
int val = 1;
int ret;
__asm__ __volatile__ ("lock; cmpxchgl %1, %2"
: "=a" (ret)
: "r" (val), "m" (*(lp)), "0"(cmp)
: "memory", "cc");
int cmp = 0;
int val = 1;
int ret;
__asm__ __volatile__ ("lock; cmpxchgl %1, %2"
: "=a" (ret)
: "r" (val), "m" (*(lp)), "0"(cmp)
: "memory", "cc");
It's not 100% apparent whether or not the Assembler in Ogre was written specifically for it, or taken from an existing library, though some of the comments included in-line with the code lead me to believe it was a little of both. From those same comments and the syntax used, the assembly code is meant for x86_64 and for most of it, more architecture agnostic versions (C++ specifically) exist, with slight performance loss. If the team is putting those kinds of comments in their own source code, I have to imagine that yes, this version of Ogre could relatively easily be ported to and built for aarch64, with very little difference to from the current x86_64 version.
Here is one of the comments on Assembly use in Ogre:
"USE_BUILTIN_FFS default: 0 (i.e., not used)
Causes malloc to use the builtin ffs() function to compute indices.
Some compilers may recognize and intrinsify ffs to be faster than the
supplied C version. Also, the case of x86 using gcc is special-cased
to an asm instruction, so is already as fast as it can be, and so
this setting has no effect. Similarly for Win32 under recent MS compilers.
(On most x86s, the asm version is only slightly faster than the C version.)"
Causes malloc to use the builtin ffs() function to compute indices.
Some compilers may recognize and intrinsify ffs to be faster than the
supplied C version. Also, the case of x86 using gcc is special-cased
to an asm instruction, so is already as fast as it can be, and so
this setting has no effect. Similarly for Win32 under recent MS compilers.
(On most x86s, the asm version is only slightly faster than the C version.)"
Saturday, 1 February 2014
OOP344 Macros Workshop
So it seems swapping int's and doubles using macros or simple, me-defined functions doesn't really change too much in terms of processing time. There is of course the possibility that I screwed up in the macro version and forgot to add something to it to speed things up, but for the most part, both version of the code process in about the same amount of time, 5 seconds and change.
There we can see, nearly six seconds for swapping integers.
It makes sense, to me at least, that using a #define macro to do the swapping instead of writing the entire function out in long form wouldn't change the times too drastically.
I mean, a #define is only going to be pasted into the main (in this case) when called, and nothing more.
It is a little comforting that the times seem to make more sense - with double's taking a slight amount longer to process than the int's, which was the reverse of my function. I do of course leave the door open that I'm completely wrong in my coding. It was also weird to go back and write code in C style after a full semester of C++ changing everything to classes. I much prefer classes but didn't feel something this size required it.
 |
| my hand written function's processing time for 1 billion swaps |
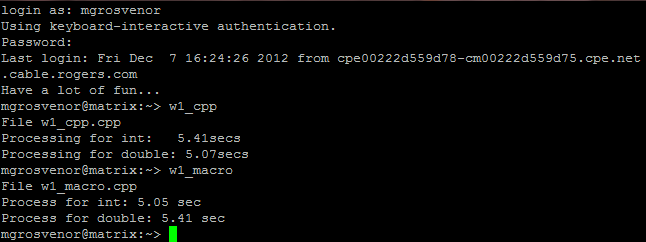 |
| Macro time to swap 1 billion times |
I mean, a #define is only going to be pasted into the main (in this case) when called, and nothing more.
It is a little comforting that the times seem to make more sense - with double's taking a slight amount longer to process than the int's, which was the reverse of my function. I do of course leave the door open that I'm completely wrong in my coding. It was also weird to go back and write code in C style after a full semester of C++ changing everything to classes. I much prefer classes but didn't feel something this size required it.
 |
| Macro code |
 |
| My function |
Farewell to 64bit Arms - Assembly, Loops, 64 Arms Part 2
So we had finished ten loops. Now we moved on to 30 for both x86 and aarch64.
From there, we had to move on to a loop of 30 while also splitting loop iterations greater than 9 into two separate digits to be inserted into the byte, and printed, and (whoops, unbeknown-st to use at the time) then remove leading zeros (eg print out "9" instead of "09").
This required a few, but not difficult changes to both x86 and aarch64 code.
Divide the loop iteration by 10, convert the 1's column of the resulting quotient (by adding zero as before), and writing it to the low half of the specified register, and while the iteration is less than 10, put a '0' in the ten's column, and compare whether or not the register holding the 10's column is holding a zero with (in our case) hex 0. If it is equal, we used je (jump if equal) to not write, or skip writing to the 10's column. If the 10's column is not '0', convert it to ascii, move it to the write byte index in our string message register.
From there on the code is mostly the same, and by this point, making the 'skip_10's' its own little function was the most work aside from keeping track of safe registers remaining (we always seem to get caught up on the little stuff). The aarch64 was, as it was before, done second and was mostly about converting between syntax. Why, when Assembly is this old, can newer versions of it not use syntax from existing variations? I mean really.
As for which I prefer of the two. x86_64 I feel has more straight forward, relatively speaking, I mean opcodes are only 3 characters long, and often times (regardless of platform syntax) have several different meanings attached to them. However, the aarch64 syntax does make keeping track of registers so much easier, with each simply having a numeric value/name from rzr to 30, and subdividing them into groups that are relatively easy to remember (and simply change letter denominations for different memory length). With that said, msub is one of those 'love to hate' opcodes that will take time to warm to after this experience. It was, with the help of Starter Kit relatively easy to write the code, compared to some other languages (C, C++), but isn't quite at the code-in-English level of say, COBOL. With more practical practice, I can see myself quite enjoying writing/working with Assembler (of either variety for this classes purpose)
Here is a link to the first teration of the code (10 iteration loop x86), and here is aarch64 version.
The finalized versions are x86 here and aarch64 here
From there, we had to move on to a loop of 30 while also splitting loop iterations greater than 9 into two separate digits to be inserted into the byte, and printed, and (whoops, unbeknown-st to use at the time) then remove leading zeros (eg print out "9" instead of "09").
This required a few, but not difficult changes to both x86 and aarch64 code.
Divide the loop iteration by 10, convert the 1's column of the resulting quotient (by adding zero as before), and writing it to the low half of the specified register, and while the iteration is less than 10, put a '0' in the ten's column, and compare whether or not the register holding the 10's column is holding a zero with (in our case) hex 0. If it is equal, we used je (jump if equal) to not write, or skip writing to the 10's column. If the 10's column is not '0', convert it to ascii, move it to the write byte index in our string message register.
cmp $0x00, %rax /* if the 10's column is 0 */
je skip_10s /* don't write it */
...
skip_10s:
mov $len, %rdx /*print out the string with the new byte*/
mov $msg, %rsi
mov $1, %rdi
mov $1, %rax
syscall
mov $len, %rdx /*print out the string with the new byte*/
mov $msg, %rsi
mov $1, %rdi
mov $1, %rax
syscall
From there on the code is mostly the same, and by this point, making the 'skip_10's' its own little function was the most work aside from keeping track of safe registers remaining (we always seem to get caught up on the little stuff). The aarch64 was, as it was before, done second and was mostly about converting between syntax. Why, when Assembly is this old, can newer versions of it not use syntax from existing variations? I mean really.
As for which I prefer of the two. x86_64 I feel has more straight forward, relatively speaking, I mean opcodes are only 3 characters long, and often times (regardless of platform syntax) have several different meanings attached to them. However, the aarch64 syntax does make keeping track of registers so much easier, with each simply having a numeric value/name from rzr to 30, and subdividing them into groups that are relatively easy to remember (and simply change letter denominations for different memory length). With that said, msub is one of those 'love to hate' opcodes that will take time to warm to after this experience. It was, with the help of Starter Kit relatively easy to write the code, compared to some other languages (C, C++), but isn't quite at the code-in-English level of say, COBOL. With more practical practice, I can see myself quite enjoying writing/working with Assembler (of either variety for this classes purpose)
Here is a link to the first teration of the code (10 iteration loop x86), and here is aarch64 version.
The finalized versions are x86 here and aarch64 here
Subscribe to:
Posts (Atom)